Du har kanskje hørt om ulike datamoduser i Microsoft Fabric og Power BI, slik som Direct Lake, Import og DirectQuery, men hva betyr de egentlig i praksis? For en bedriftseier er det viktigste å forstå hvordan disse valgene påvirker rapportenes ytelse, hvor ferske dataene er, og hvilke hensyn som må tas i bruk.
Tradisjonelt har Power BI gitt oss to hovedvalg for hvordan data hentes inn i rapporter. Microsoft Fabric introduserer en tredje, spennende mulighet: Direct Lake. La oss bryte ned hva disse betyr, og hva Direct Lake tilfører.
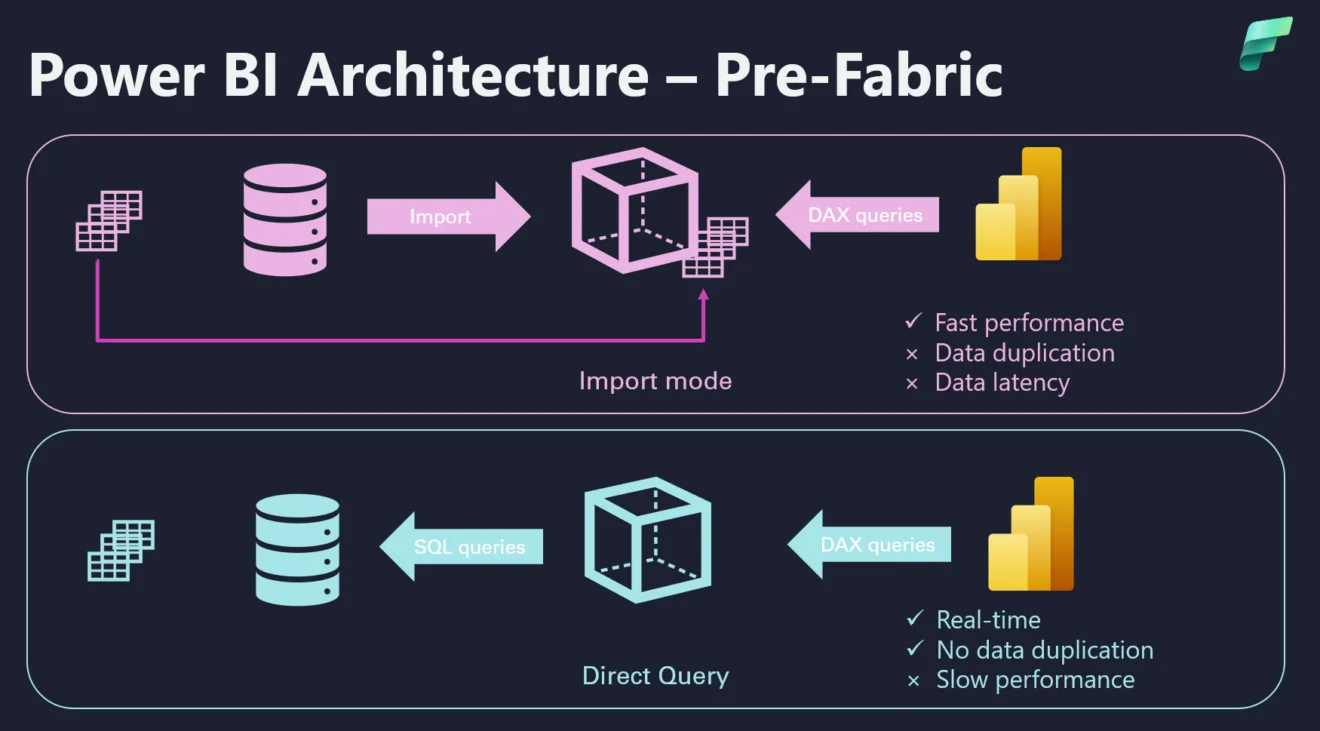
De Tradisjonelle Valgene: Import og DirectQuery
Før vi ser på Direct Lake, er det nyttig å forstå de to modusene som har vært standard i Power BI lenge:
1. Import-modus
- Hvordan det fungerer: Data kopieres fra kildesystemet (f.eks. en database, Excel-fil) og lastes inn i Power BIs egen, høytytende minnebaserte motor (VertiPaq).
- Fordeler: Rask ytelse for rapportering og analyse, siden dataene ligger lokalt i Power BI. Gir full fleksibilitet med DAX (Power BIs formelspråk).
- Ulemper: Dataene er bare så ferske som sist de ble importert (oppdatert). Krever planlagte oppdateringer. Kan ha begrensninger på datamengde (selv om dette er blitt mye bedre med Premium/Fabric-kapasiteter).
2. DirectQuery-modus
- Hvordan det fungerer: Power BI sender spørringer direkte til den opprinnelige datakilden hver gang en bruker interagerer med rapporten. Ingen data kopieres permanent inn i Power BI.
- Fordeler: Dataene i rapporten er alltid så ferske som dataene i kilden. Egner seg godt for svært store datasett som ikke får plass i Import-modus.
- Ulemper: Ytelsen avhenger helt av kildesystemet. Komplekse rapporter mot trege kilder kan bli langsomme. Ikke alle DAX-funksjoner er tilgjengelige.
Den Nye Stjernen: Direct Lake
Microsoft Fabric introduserer en ny og kraftfull måte å koble Power BI til data som ligger lagret i Fabric's OneLake (spesifikt i et Lakehouse eller Warehouse): Direct Lake.
Hva er Direct Lake?
- Hvordan det fungerer: Direct Lake er en banebrytende teknologi som lar Power BI-motoren lese data direkte fra Delta-tabeller (det åpne formatet som brukes i Fabric Lakehouse/Warehouse) i OneLake. Det er ingen kopiering eller import av data inn i en separat Power BI-modell, og det er heller ingen oversettelse av spørringer slik som i DirectQuery. Power BI forstår Delta-formatet direkte. Data lastes inn i minnet etter behov (on-demand) når en bruker spør etter dem.
- Forutsetning: Dataene må ligge i et Fabric Lakehouse eller Warehouse på en Fabric-kapasitet.
Fordelene med Direct Lake: Det Beste fra Begge Verdener?
Direct Lake kombinerer mange av fordelene fra både Import og DirectQuery:
- Lynrask Ytelse: Ytelsen nærmer seg den du får med Import-modus, fordi Power BI leser de optimaliserte Delta/Parquet-filene direkte.
- Oppdaterte Data (med kontroll): Siden dataene leses direkte fra OneLake, kan rapportene reflektere endringer i Lakehouse/Warehouse nesten umiddelbart hvis ønskelig. Dette styres via mekanismer kalt Framing og Automatic Updates.
- Skalerbarhet for Store Datasett: Kan håndtere datasett som er for store for tradisjonell Import-modus, akkurat som DirectQuery (men med kapasitetsgrenser).
- Forenklet Dataflyt: Reduserer behovet for å administrere og planlegge separate dataoppdateringer for selve Power BI-modellen.
- Samlet Plattform: Forsterker fordelen med Fabric der data lagres én gang i OneLake og kan brukes direkte av Power BI.
Hvordan Sikres Dataferskhet i Direct Lake? (Framing vs. Automatic Updates)
Selv om Direct Lake leser direkte fra OneLake, betyr det ikke nødvendigvis at du alltid ser absolutt siste mikrosekunds endring. Du har kontroll:
- Framing: Dette er standardmetoden. Når en Direct Lake-modell oppdateres (manuelt, planlagt eller via API), skjer en rask operasjon kalt framing. Modellen sjekker da hvilke datafiler i OneLake som var de nyeste på det tidspunktet. Fremtidige spørringer vil bruke data fra disse filene. Dette gir konsistente resultater basert på et definert tidspunkt, noe som er bra under f.eks. større datalastinger.
- Automatic Updates (Valgfritt): Du kan aktivere automatiske oppdateringer for en Direct Lake-modell. Da vil modellen automatisk plukke opp de aller nyeste datafilene som blir tilgjengelige i OneLake, uten å vente på en framing-operasjon. Dette gir mer nær sanntidsdata, men kan gi litt mindre forutsigbare resultater hvis underliggende data endres mens en bruker analyserer.
Valget mellom disse avhenger av behovet for absolutt ferske data versus behovet for garantert konsistens under analyse.
Fallback til DirectQuery og Kapasitetsgrenser
Selv om Direct Lake er designet for høy ytelse, finnes det situasjoner der Power BI må falle tilbake til å bruke den tregere DirectQuery-metoden mot Lakehouse/Warehouse sin SQL-endepunkt:
- Visninger (Views): Hvis modellen din bruker visninger fra Lakehouse/Warehouse i stedet for direkte tabeller.
- Sikkerhetsregler (RLS/OLS): Hvis du bruker sikkerhet på radnivå (RLS) eller objektnivå (OLS) definert i selve Lakehouse/Warehouse (SQL-endepunktet).
- Kapasitetsgrenser: Hvis datamodellen overskrider visse grenser for din Fabric-kapasitet. Dette er et viktig punkt å forstå.
- Komplekse Kolonnetyper/Funksjoner: Visse datatyper eller komplekse DAX-funksjoner kan også trigge fallback.
Direct Lake Kapasitetsgrenser og Fallback
Hver Fabric-kapasitet (SKU) har bestemte grenser for hvor store Direct Lake-modeller den kan håndtere optimalt. Tabellen under viser noen nøkkelgrenser. Overskrider modellen grensen for Max model size on disk/OneLake (GB), vil alle spørringer mot den modellen falle tilbake til DirectQuery.
| Fabric SKU | Max Parquet Files / Table | Max Row Groups / Table | Max Rows / Table (Millions) | Max Model Size on Disk/OneLake (GB) | Max Memory (GB) 1 |
|---|---|---|---|---|---|
| F2 | 1,000 | 1,000 | 300 | 10 | 3 |
| F4 | 1,000 | 1,000 | 300 | 10 | 3 |
| F8 | 1,000 | 1,000 | 300 | 10 | 3 |
| F16 | 1,000 | 1,000 | 300 | 20 | 5 |
| F32 | 1,000 | 1,000 | 300 | 40 | 10 |
| F64/FT1/P1 | 5,000 | 5,000 | 1,500 | Unlimited | 25 |
| F128/P2 | 5,000 | 5,000 | 3,000 | Unlimited | 50 |
| F256/P3 | 5,000 | 5,000 | 6,000 | Unlimited | 100 |
| F512/P4 | 10,000 | 10,000 | 12,000 | Unlimited | 200 |
| F1024/P5 | 10,000 | 10,000 | 24,000 | Unlimited | 400 |
| F2048 | 10,000 | 10,000 | 24,000 | Unlimited | 400 |
| 1 Max Memory er en øvre grense for hvor mye data som kan lastes inn i minnet for Direct Lake. Overskridelse trigger ikke nødvendigvis fallback, men kan påvirke ytelsen negativt på grunn av økt datautveksling (paging) mellom minne og OneLake. | |||||
Hvorfor unngå fallback? Fallback til DirectQuery betyr vanligvis tregere rapportytelse. Det er derfor viktig å optimalisere Delta-tabellene i Lakehouse/Warehouse (f.eks. vedlikehold og V-Order) og velge riktig størrelse på Fabric-kapasiteten (SKU) for å unngå unødvendig fallback og ekstra kostnader.
Sammenligning: Direct Lake vs. Import vs. DirectQuery
Den andre tabellen gir en god oversikt over forskjellene i funksjonalitet:
| Egenskap | Direct Lake | Import | DirectQuery |
|---|---|---|---|
| Lisensiering | Kun Fabric Kapasitet (F-SKU) | Alle Fabric/Power BI lisenser | Alle Fabric/Power BI lisenser |
| Datakilde | Kun Fabric Lakehouse/Warehouse | Alle støttede kilder | Kilder som støtter DirectQuery |
| Data Ferskhet | Nesten sanntid (Auto Updates) eller ved oppdatering (Framing) | Ved siste import/oppdatering | Sanntid (som i kilden) |
| Ytelse (Typisk) | Høy (minnebasert lesing) | Høy (minnebasert) | Variabel (avhenger av kilde) |
| Datavolum | Store volum (men kapasitetsgrenser for minne/disk trigger fallback) | Begrenset av minne (varierer med kapasitet) | Store volum (ikke begrenset av Power BI-minne) |
| Modellkompleksitet (DAX) | Høy (med potensielt fallback) | Høyest (full fleksibilitet) | Begrenset (ikke alle funksjoner støttes) |
| Dataflyt/Oppdatering | Forenklet (ingen separat PBI-modell oppdatering) | Krever separat PBI-modell oppdatering | Ingen PBI-modell oppdatering nødvendig |
| Fallback til DirectQuery | Ja, i visse tilfeller (Views, RLS i kilde, grenser etc.) | Nei | Ikke relevant |
| Komposittmodeller | Nei (kan ikke blandes direkte med Import/DQ i samme modell) 1 | Ja (med DQ/Dual) | Ja (med Import/Dual) |
| 1 Man kan lage en komposittmodell på toppen av et Direct Lake datasett i Power BI Desktop. | |||
Når Bruker Du Hva? (Oppdatert Anbefaling)
Med den nye innsikten, hvordan velger du riktig modus?
- Direct Lake: Bør være standardvalget når dataene dine ligger i et Fabric Lakehouse eller Warehouse. Konfigurer om du vil bruke standard framing eller automatic updates basert på ferskhetskrav. Vær obs på kapasitetsgrenser og andre situasjoner som kan føre til fallback, og design/optimaliser for å unngå det hvis mulig.
- Import: Fortsatt et godt valg for:
- Mindre datasett der du trenger maksimal ytelse og full DAX-fleksibilitet.
- Når datakilden din ikke er et Fabric Lakehouse/Warehouse.
- Når du trenger kompleks modellering som er best egnet for VertiPaq-motoren.
- DirectQuery: Brukes primært når:
- Datakilden din er et støttet system utenfor Fabric og ikke kan flyttes/speiles.
- Du har et absolutt krav om sanntidsdata fra en ekstern kilde.
- Du må bruke funksjonalitet som trigger fallback, og aksepterer den potensielle ytelsesreduksjonen.
Konklusjon: Raskere Innsikt, Enklere Arkitektur (Med Viktige Hensyn)
Direct Lake er en sentral innovasjon i Microsoft Fabric, og tilbyr en kraftfull kombinasjon av ytelsen fra Import-modus og ferskheten/skalerbarheten fra DirectQuery. For deg som bedriftseier betyr dette potensial for raskere rapporter, mer oppdaterte data for beslutningstaking, og en enklere dataarkitektur.
Det er imidlertid avgjørende å forstå mekanismene som styrer dataferskhet (framing/automatic updates) og ikke minst kapasitetsgrensene og andre situasjoner som kan føre til ytelsesreduserende fallback til DirectQuery. Riktig design av Lakehouse/Warehouse, optimalisering av Delta-tabeller og valg av passende Fabric-kapasitet er nøkkelen for å få mest mulig ut av Direct Lake.
Er du usikker på hvordan du best designer for Direct Lake, velger riktig kapasitet, eller navigerer i de ulike modusene i Fabric? Vi i TrendMe kan hjelpe deg.
Ta kontakt for en prat om hvordan vi kan optimalisere din dataflyt og rapportytelse!