Når du dykker ned i Microsoft Fabric, vil du raskt møte på to sentrale begreper for datalagring og analyse: Warehouse og Lakehouse. Begge er bygget på den åpne Delta Lake-standarden og lagrer data i OneLake, men de er designet for litt ulike formål og brukere. Å velge riktig (eller en kombinasjon) er viktig for å bygge en effektiv dataplattform.
I dette innlegget ser vi nærmere på hva et Warehouse og et Lakehouse er i Fabric, hva som skiller dem, og når du bør vurdere den ene fremfor den andre.
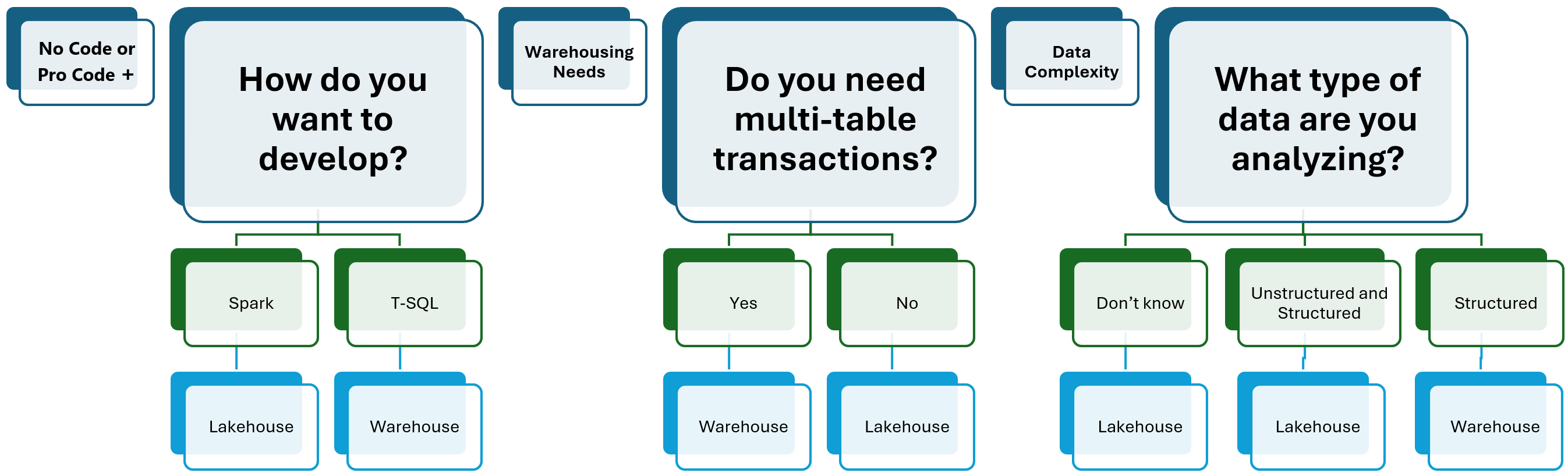
Hva er et Warehouse i Fabric?
Et Fabric Warehouse er det du kan kalle et tradisjonelt, men moderne, datavarehus. Det er designet for:
- Strukturert data: Optimalisert for tabeller med rader og kolonner.
- SQL-utviklere og analytikere: Hovedspråket er
T-SQLfor datainnlasting, transformasjon (ETL/ELT), modellering og querying. - Business Intelligence (BI): Tett integrert med Power BI for rapportering og dashboards.
- Transaksjoner (ACID): Støtter fullt ut transaksjoner på tvers av flere tabeller, noe som sikrer datakonsistens ved komplekse skriveoperasjoner.
- Ytelse og Skalerbarhet: Bygget for høy ytelse på SQL-spørringer, med automatisk skalering av data og regnekraft (compute).
Tenk på Warehouse når du trenger en robust plattform for bedriftens "single source of truth" for strukturerte data, spesielt for BI-formål, og hvor T-SQL-kompetanse er utbredt.
Hva er et Lakehouse i Fabric?
Et Fabric Lakehouse er en mer fleksibel dataarkitekturplattform som kombinerer det beste fra Data Lakes (rådatalagring) og Data Warehouses (strukturert analyse). Det er designet for:
- Alle typer data: Kan lagre og behandle både strukturert (tabeller) og ustrukturert data (filer som CSV, JSON, Parquet, bilder etc.) i OneLake.
- Data Engineers og Data Scientists: Hovedverktøyene er ofte
Spark(med Python, Scala, R, Spark SQL) for datatransformasjon, engineering og maskinlæring. - Fleksibilitet: Gir større frihet til å organisere data (f.eks. i en Medallion-arkitektur med Bronze, Silver, Gold-lag).
- Åpenhet: Data lagres i åpent
Delta Lake-format, tilgjengelig for ulike verktøy.
Det Viktige SQL-Endepunktet
En nøkkelfunksjon ved Lakehouse er at Fabric automatisk oppretter et SQL Analytics Endpoint for hvert Lakehouse. Dette endepunktet lar deg:
- Querye
Delta-tabellene i Lakehouse ved hjelp avT-SQL(samme språk som i Warehouse). - Koble til Power BI (
DirectLake-modus for topp ytelse uten import!) og andre SQL-kompatible verktøy.
MEN, og dette er en viktig begrensning: SQL-endepunktet til et Lakehouse er primært for leseoperasjoner. Du kan opprette views og noen funksjoner, men du kan ikke bruke det til å laste data med INSERT/UPDATE/DELETE (DML) eller gjøre omfattende endringer i tabellstrukturen (DDL) via T-SQL slik du kan i et Warehouse. Datainnlasting og transformasjon i Lakehouse skjer typisk via Spark, Dataflows eller Pipelines.
Warehouse vs. Lakehouse: Hovedforskjeller og Begrensninger
| Egenskap | Warehouse | Lakehouse (via SQL Endpoint) |
|---|---|---|
| Primært Bruksområde | Enterprise Data Warehousing, BI, strukturert analyse | Datateknikk, Data Science, analyse av Delta-tabeller, staging, utforsking |
| Datatyper | Primært strukturert | Strukturert og ustrukturert (SQL EP leser kun Delta-tabeller) |
| Hovedspråk/-verktøy | T-SQL |
Spark (Python/Scala/SQL), Dataflows, Pipelines (men T-SQL for lesing via SQL EP) |
Skriveoperasjoner (T-SQL DML) |
Ja (Full støtte) | Nei (Kun Lese) |
| Transaksjoner (ACID) | Ja (Full støtte) | Nei (via SQL EP), men Delta Lake-formatet gir ACID på filnivå via Spark. |
Tabell-endringer (T-SQL DDL) |
Ja (Full støtte) | Begrenset (Views, TVFs - ikke CREATE TABLE, ALTER TABLE etc.) |
"Better Together": Når Bruker Man Begge?
Ofte er ikke svaret enten/eller, men heller hvordan man best kombinerer styrkene til begge. En vanlig tilnærming er Medallion-arkitekturen:
- Lakehouse (Bronze & Silver): Brukes til å lande rådata (Bronze) og deretter rense, transformere og berike dataene (Silver) ved hjelp av
Sparkeller Dataflows. Her håndteres både strukturert og ustrukturert data. - Warehouse (Gold): Data fra Silver-laget lastes inn i Warehouse. Her skjer den siste modelleringen for BI-formål, aggregering og optimalisering for rapportering. Warehouse blir da kilden for Power BI-rapporter og sluttbrukeranalyser som krever høy ytelse og
T-SQL-funksjonalitet.
Fabric gjør det også enkelt å koble sammen Warehouse og Lakehouse ved hjelp av Shortcuts og kryss-database-spørringer, slik at du kan få tilgang til data uten å måtte kopiere dem fysisk.
Konklusjon: Hva Bør Du Velge?
Valget avhenger av dine behov:
- Trenger du en klassisk datavarehusløsning med full
T-SQL-støtte, transaksjoner og primært strukturert data for BI? Da er Warehouse et godt utgangspunkt. - Trenger du fleksibilitet til å håndtere ulike datatyper (også ustrukturerte), jobber mye med
Spark/Python, og trenger et staging-område eller en plattform for data science? Da er Lakehouse veien å gå. Husk begrensningene i SQL-endepunktet for skriving. - Har du komplekse behov og vil bygge en moderne dataplattform fra rådata til ferdige rapporter? Da er en kombinasjon av Lakehouse og Warehouse ofte den beste og mest robuste løsningen.
Det kan være utfordrende å navigere i de ulike alternativene. Vi i TrendMe har erfaring med å designe og implementere effektive dataløsninger i Microsoft Fabric og kan hjelpe deg med å velge riktig arkitektur for din bedrift.
Ta kontakt for en prat om hvordan vi kan bistå dere!