Når du bygger dataløsninger i Microsoft Fabric, enten det er et Warehouse, et Lakehouse, eller en Power BI-datamodell (semantisk modell), er måten du strukturerer dataene på helt avgjørende for både ytelse og brukervennlighet. To svært vanlige designmønstre du vil støte på er Stjerneskjema (Star Schema) og Snøfnuggskjema (Snowflake Schema).
Men hva er egentlig forskjellen, og hvilken bør du velge for dine Fabric- og Power BI-løsninger? Hos TrendMe ser vi at dette valget har stor betydning. La oss bryte ned disse konseptene.
Hva er et Stjerneskjema? Enkelt og Effektivt
Et stjerneskjema er den mest brukte og generelt anbefalte modellen for datavarehus og BI-løsninger. Det har en intuitiv struktur:
- Faktatabell (Fact Table): Én sentral tabell som inneholder målinger (metrics) eller forretningshendelser (f.eks. salgstransaksjoner, loggføringer, målinger fra sensorer). Den inneholder numeriske verdier som kan aggregeres (summeres, telles, beregne gjennomsnitt osv.) og fremmednøkler som kobler til dimensjonstabellene.
- Dimensjonstabeller (Dimension Tables): Flere tabeller som "stråler ut" fra faktatabellen (derav navnet "stjerne"). Hver dimensjonstabell beskriver forretningskonteksten – hvem, hva, hvor, når, hvorfor – knyttet til faktaene (f.eks. Kunder, Produkter, Datoer, Geografi, Salgskanal). De inneholder beskrivende attributter (tekst, datoer, flagg) som brukes for filtrering, gruppering og segmentering i analyser.
Kjennetegnet på et rent stjerneskjema er at hver dimensjonstabell er direkte koblet til faktatabellen med en én-til-mange-relasjon. Dimensjonstabellene er typisk denormaliserte. Det betyr at en dimensjonstabell (f.eks. Produkt) kan inneholde både produktnavn, kategori og underkategori i samme tabell, selv om det teknisk sett innebærer en viss dataredundans (kategorinavnet gjentas for hvert produkt i den kategorien).
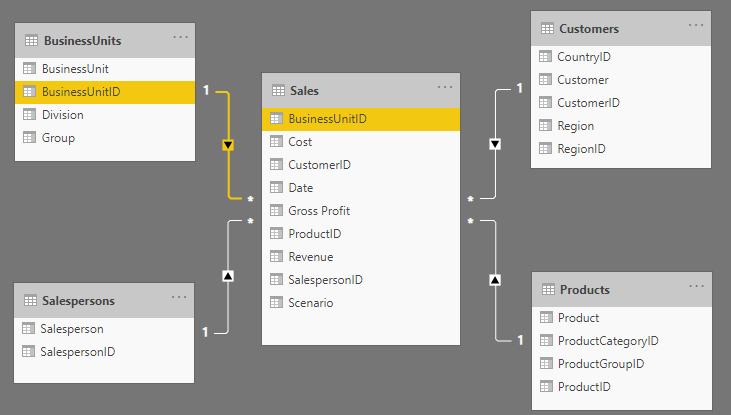
Hva er et Snøfnuggskjema? Mer Normalisert, Mer Komplekst
Et snøfnuggskjema ligner på et stjerneskjema, men med en viktig forskjell: dimensjonstabellene er normaliserte. Det betyr at en dimensjon kan være brutt ned i flere relaterte tabeller for å redusere dataredundans og potensielt spare lagringsplass.
For eksempel, i stedet for én flat Produkt-dimensjon, kan et snøfnuggskjema ha:
- En Produkttabell (med produktnavn, nøkkel til underkategori).
- En Underkategoritabell (med underkategorinavn, nøkkel til kategori).
- En Kategoritabell (med kategorinavn).
Faktatabellen kobler seg kanskje bare direkte til den mest detaljerte dimensjonstabellen (Produkttabellen i dette eksempelet). For å få tak i attributter fra høyere nivåer (som kategorinavnet), må spørringer utføre flere JOINs ("hoppe" via de relaterte dimensjonstabellene). Dette skaper en mer forgrenet struktur som kan ligne et snøfnugg.
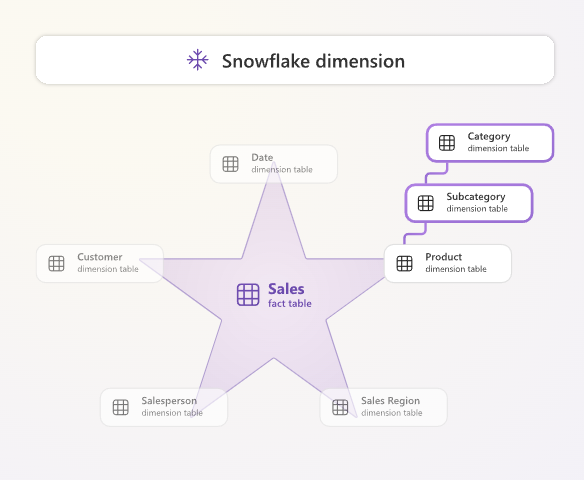
Stjerne vs. Snøfnugg: Hovedforskjellene Oppsummert
| Egenskap | Stjerneskjema | Snøfnuggskjema |
|---|---|---|
| Dimensjonsstruktur | Denormalisert (én tabell per dimensjon) | Normalisert (dimensjoner brutt ned i flere tabeller) |
| Antall Tabeller | Færre | Flere |
| Antall JOINs for Spørringer | Færre (typisk bare fakta ↔ dimensjoner) | Flere (kan kreve dimensjon ↔ dimensjon JOINs) |
| Spørringsytelse (Generelt) | Raskere (færre JOINs) | Kan være Tregere (flere JOINs) |
| Lagringsplass | Kan kreve litt Mer (pga. redundans) | Kan kreve litt Mindre (pga. normalisering) |
| Dataintegritet/Oppdatering | Enklere integritet innenfor én dimensjon | Lettere å oppdatere normaliserte attributter (f.eks. endre kategorinavn på ett sted) |
| Brukervennlighet/Forståelse | Enklere å forstå og bruke | Mer kompleks å navigere |
| Best Egnet For | Datavarehus, BI, Analyse (Power BI/Fabric) | Operasjonelle systemer (OLTP), Kildedata |
Hvorfor er Stjerneskjemaet Anbefalt for Fabric og Power BI?
Selv om snøfnuggskjemaet kan virke mer "korrekt" fra et tradisjonelt databasenormaliseringsperspektiv og kan spare litt lagringsplass, er det en nesten universell anbefaling å bruke stjerneskjemaet for datamodeller i Power BI (semantiske modeller) og for det analytiske rapporteringslaget (ofte kalt "Gull-laget" i en Medallion-arkitektur) i Fabric Lakehouses/Warehouses. Hvorfor?
- Ytelse: Power BI's VertiPaq-motor (og DirectLake-modusen i Fabric) er høyt optimalisert for stjerneskjemaer. Færre JOINs mellom tabeller betyr nesten alltid raskere spørringer og mer responsive rapporter. Ytelsesgevinsten ved færre JOINs veier vanligvis mye tyngre enn den marginale lagringsbesparelsen ved normalisering i analytiske modeller.
- Brukervennlighet: En enklere modell med færre tabeller er betydelig lettere for rapportutviklere og sluttbrukere å forstå, navigere og bruke effektivt. Det blir enklere å finne de riktige feltene for filtrering og analyse i Power BI's Data-panel, og reduserer risikoen for feilaktige koblinger eller tolkninger.
- Enkelhet i DAX: Beregninger i DAX (Data Analysis Expressions), språket for Power BI-mål og beregnede kolonner, blir ofte enklere å skrive, lese og feilsøke i et stjerneskjema. Kompleksiteten med å håndtere relasjoner over flere nivåer (som i snøfnugg) unngås.
- Hierarkier i Power BI: Power BI lar deg enkelt lage hierarkier innenfor én tabell (f.eks. Kategori -> Underkategori -> Produkt). Dette er ikke direkte mulig hvis hierarkiet spenner over flere normaliserte tabeller (som i et snøfnugg). Denormalisering til én dimensjonstabell løser dette elegant.
Derfor er den klare anbefalingen fra Microsoft og de fleste eksperter: Design dine Power BI semantiske modeller og analytiske lag i Fabric som stjerneskjemaer.
Men Hva Om Kildedataene Mine Er Et Snøfnugg?
Dette er en veldig vanlig situasjon! Operasjonelle kildesystemer (OLTP-databaser, ERP, CRM) er ofte høyt normaliserte (ligner snøfnugg) for å sikre dataintegritet og effektivitet for transaksjoner. Hva gjør du da?
Svaret er å transformere dataene som en del av datainnlastingsprosessen (ETL/ELT) i Fabric, slik at resultatet blir et stjerneskjema i det analytiske laget. Bruk verktøyene i Fabric til å denormalisere dimensjonene før de når Power BI-modellen eller Gull-laget ditt:
- I Power Query (brukes i Dataflows Gen2 / Power BI Desktop): Bruk transformasjonen "Merge Queries" (Slå sammen spørringer) for å kombinere de relaterte, normaliserte dimensjonstabellene (f.eks. slå sammen Produkt, Underkategori og Kategori) til én enkelt, "flat" dimensjonstabell (f.eks. en DimProduct som inneholder alle tre nivåene som kolonner).
- I Lakehouse/Warehouse (ved bruk av Spark Notebooks eller T-SQL): Utfør de nødvendige JOIN-operasjonene når du transformerer data fra et tidligere lag (f.eks. Sølv-laget) til Gull-laget. Målet er å skape denormaliserte dimensjonstabeller klare for rapportering. Vurder bruk av Views eller Materialized Views for å forenkle dette.
Målet er at sluttproduktet som analytikere og rapportbrukere interagerer med (Power BI-modellen / Gull-datasettet) har en ren og effektiv stjernestruktur, uavhengig av hvordan kildedataene så ut.
Finnes Det Unntak Hvor Snøfnugg Er OK i Power BI/Fabric?
Som med de fleste designprinsipper, finnes det sjeldne unntak.
- Svært Store Dimensjoner (Many-to-Many): I noen tilfeller med ekstremt store dimensjoner eller komplekse mange-til-mange-relasjoner, kan en brotabell (som teknisk sett bryter det rene stjerneskjemaet) være nødvendig.
- Avanserte DAX-Scenarier: Noen svært spesifikke DAX-mønstre (som å håndtere visse typer filterkontekst-utfordringer eller "auto-exist") kan i sjeldne tilfeller dra nytte av en snøfnugg-lignende struktur for en bestemt dimensjon.
Disse unntakene bør imidlertid vurderes nøye og kun implementeres hvis man har en veldig god grunn og fullt ut forstår konsekvensene for ytelse, kompleksitet og brukervennlighet. For 99% av vanlige BI- og analysesenarioer: Hold deg til stjerneskjemaet.
Oppsummering: Stjernen Skinner Klarest for Analyse
Både stjerne- og snøfnuggskjemaer er valide metoder for å organisere data. Mens snøfnuggskjemaet utmerker seg ved å redusere redundans gjennom normalisering (ideelt for kildesystemer), gir stjerneskjemaets enkelhet og denormaliserte dimensjoner betydelige og avgjørende fordeler for spørringsytelse, modellkompleksitet og brukervennlighet i analytiske plattformer som Microsoft Fabric og Power BI.
Den klare og sterke anbefalingen er derfor å designe dine analytiske datamodeller og rapporteringslag som stjerneskjemaer. Hvis kildedataene dine er normaliserte (snøfnugg), invester tid i transformasjonsprosessen for å skape et optimalt stjerneskjema før dataene når sluttbrukerne og analyseverktøyene.
Trenger du hjelp med å designe en optimal datamodell for dine spesifikke behov i Fabric eller Power BI, eller med å transformere komplekse kildedata? Ta kontakt med oss i TrendMe for en uforpliktende prat. Vi har ekspertisen til å bygge dataløsninger som er både kraftfulle, effektive og enkle å bruke. Du kan også lese mer om våre Microsoft Fabric tjenester eller Power BI tjenester.